
许久未见,小白日志再次更新啦!!!相信各位都有了很大的进步与提升。今天,我们第三期在基因组(链接)和差异(链接)之后进一步为大家介绍在转录分析中经常用到的数据库,这些数据库无论是在基因功能注释或是在富集分析方向等等都被广泛运用。而对这些数据库有个基础的认知就显的十分重要,因此今天我们就来一起聊聊关于数据库的那些事儿。
01
NR/NT数据库
NR(Non-Redundant Protein Sequence Database)非冗余蛋白库,所有GenBank+EMBL+DDBJ+PDB中的非冗余蛋白序列,对于所有已知的或可能的编码序列,NR记录中都给出了相应的氨基酸序列(通过已知或可能的读码框推断而来)以及专门蛋白数据库中的序列号。NR库相当于一个以核酸序列为基础的交叉索引,将核酸数据和蛋白数据联系起来。NT(Nucleotide Sequence Database),核酸序列数据库。
NR和NT库都可以通过NCBI(National Center for Biotechnology Information,美国国立生物技术信息中心)进行在线BLAST,也可以在ftp://ftp.ncbi.nih.gov/blast/db地址中将数据直接下载下来进行本地比对,需要注意的是,NR和NT库是被切分为以数字命名的子数据库上传的(如下图所示),将所有的子数据库放到同一个目录下,解压缩后构建索引文件即可。
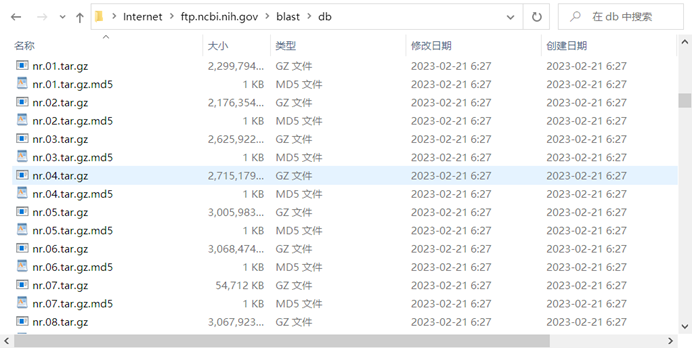
图1.数据库下载后目录
02
GO数据库
GO(gene ontology)是基因本体联合会(Gene Onotology Consortium)所建立的数据库,旨在建立一个适用于各种物种的,对基因和蛋白质功能进行限定和描述的,并能随着研究不断深入而更新的语言词汇标准。GeneOntology(GO)最初是由1988年对三个模式生物数据库的整合开始:FlyBase(果蝇数据库Drosophila),Saccharomyces Genome Database(酵母基因组数据库SGD)和the Mouse Genome Database(小鼠基因组数据库MGD)。从那开始,GO不断发展扩大,现在已包含数十个动物、植物、微生物的数据库。GO发展了具有三级结构的标准语言(ontology),根据基因产物的相关分子功能、生物学途径、细胞学组件而给予定义,无物种相关性。
(1)分子功能(Molecular Function,MF)单个的基因产物(包括蛋白质和RNA)或多个基因产物的复合物在分子水平上的活动,比如“催化”,“转运”。为避免基因产物名称与其分子功能之间的混淆,GO分子功能通常附加“活性(activity)”一词。比如,蛋白激酶(protein kinase)具有GO分子功能:蛋白激酶活性( protein kinase activity);
(2)细胞组分(Cellular Component,CC)基因产物在执行功能时所处的细胞结构位置,比如在线粒体,核糖体;
(3)生物过程(Biological Process,BP)通过多种分子活动完成的生物学过程。
GO的基本单元是term,每个term有一个唯一的标示符(由“GO:"加上7个数字组成)和一个term名,比如 GO:1904659(葡萄糖跨膜转运),每个term都属于一个ontology,比如 GO:1904659属于生物过程(Biological Process)。Gene Ontology的结构是一个有向无环图,Gene Ontology 的结构中每一个 term可以有不止一个上一级。GO数据库在生物医学研究方面发挥着至关重要的作用,并已被用于数以万计的科学研究。GO注释最常见的用途是大规模的分子生物学(组学)研究,以深入了解生物体的结构、功能和动力学。GO富集分析用于在控制的实验条件下发现统计学上显著的相似性或差异性。
图2.GO数据库
03
KEGG数据库
KEGG(Kyoto Encyclopedia of Genes and Genomes,京都基因与基因组百科全书)。是一个整合了基因组、化学和系统功能信息的数据库,旨在揭示生命现象的遗传与化学蓝图。它是由人工创建的一个知识库,是基于使用一种可计算的形式捕捉和组织实验得到的知识而形成的系统功能知识库。另外,KEGG具有强大的图形功能,它利用图形来介绍众多的代谢途径以及各途径之间的关系。基因组信息存储在GENES数据库里,包括完整和部分测序的基因组序列;功能信息存储在PATHWAY数据库里,包括图解的细胞生化过程,如代谢、膜转运、信号传递、细胞周期,以及同系保守的子通路信息;LIGAND数据库包括关于化学物质、酶分子、酶反应等信息。
图3.KEGG数据库
通过与世界上其他一些大型生物信息学数据库的连接,KEGG可以为研究者提供更为丰富的生物学信息(LinkDB)。KEGG提供了Java的图形工具来访问基因组图谱,比较基因组图谱和操作表达图谱,以及其他序列比较、图形比较和通路计算的工具。KEGG建立了KEGG直系同源系统(the KEGG Orthology(KO) System),通过把分子网络的相关信息连接到基因组中,从而发展和促进了跨物种注释流程。KEGG是一个综合数据库,它们大致分为系统信息、基因组信息和化学信息三大类。进一步可细分为16个主要的数据库。可以通过不同的颜色编码来区分。
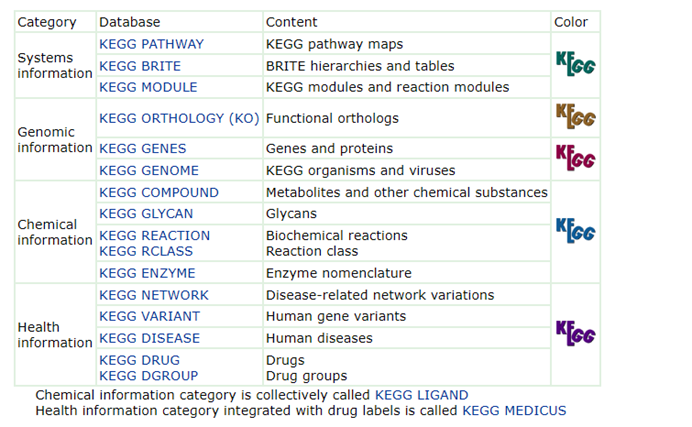
图4.KEGG数据库主要分类
04
KOG数据库
“KOG”是Clusters of orthologous groups for eukaryotic complete genomes(真核生物蛋白质直系同源簇)的缩写。KOG数据库是NCBI开发的用于同源蛋白注释的数据库,是将7个真核生物(人,拟南芥,线虫,酿酒酵母等)的完整基因组的编码蛋白,根据系统进化关系分类构建而成。KOG数据库按照功能一共可以分为二十六类,每个类别用一个字母表示,比如字母A表示RNA processing and modification。通过与KOG数据库的比对,可以很好的预测蛋白质的功能。构成每个KOG的蛋白都是被假定为来自于一个祖先蛋白,并且因此或者是orthologs或者是paralogs。Orthologs是指来自于不同物种的由垂直家系(物种形成)进化而来的蛋白,并且典型的保留与原始蛋白有相同的功能。Paralogs是那些在一定物种中的来源于基因复制的蛋白,可能会进化出新的与原来有关的功能。原核生物的蛋白质直系同源簇数据库称为COG数据库。
图5.KOG数据库
05
Swiss-Prot数据库
Swiss-Prot 是一个人工注释的蛋白质序列数据库。它拥有注释可信度高,冗余度小的优点。它是由欧洲生物信息学研究所 EBI 与瑞士生物信息学研究所 SIB 共同管理的。Swiss-Prot是UniProt数据库的子库之一,Uniprot (Universal Protein)是包含蛋白质序列,功能信息,研究论文索引的蛋白质数据库,整合了包括EBI(European Bioinformatics Institute,欧洲生物信息学研究所),SIB(the Swiss Institute of Bioinformatics,瑞士生物信息学研究),PIR(Protein Information Resource,美国国家生物医学研究基金会)三大数据库的资源。
图6.Swiss-Prot数据库
Swiss-Prot条目的注释中使用了一系列序列分析工具。包括手动评估,计算机预测,并选择结果包含在相应的条目中。这些预测包括翻译后修饰,跨膜结构域和拓扑,信号肽,结构域识别和蛋白质家族分类。来自相同基因和相同物种的序列合并到相同的数据库条目中。确定序列之间的差异包含:可变剪接,自然变异,错误的起始位点,错误的外显子边界,移码,未识别的冲突。注释会用相关出版物通过搜索数据库(例如PubMed)进行识别。阅读每篇论文的全文,然后提取信息并将其添加到条目中。科学文献中的注释包括蛋白质和基因名称,功能和亚细胞定位等信息。
Swiss-Prot注释信息示例说明:

Q9THP7:UniProt ID号
CLC2D_HUMAN:是UniProt 的登录名
C-type lectin domain family 2 member D:蛋白质名称
OS=Homo sapiens:OS是Organism简称,物种是Homo sapiens(人)
OX=9606:Organism Taxonomy,物种的分类数据库Taxonomy ID是9606(人)
GN=CLEC2D:Gene name,基因名为CLEC2D
PE=1:Protein Existence,蛋白质可靠性,对应1-5的数字,数字越小越可靠
SV=1:Sequence Version,序列版本号是1
总 结
在生物信息学领域,结合数据库的分析必不可少。不同的数据库均整合了大量的共享数据,可以进行深度的数据挖掘,包括比对、聚类、预测等等方向;而正确的了解及认知数据库的功能就是进行挖掘的第一步。
在生物信息学领域,NR/NT数据库常用于蛋白质同源性分析和序列比对;GO数据库可以为基因功能注释和基因表达分析提供帮助;KEGG数据库可以为研究提供功能基因组学、系统生物学、代谢途径、疾病等方面的信息;KOG/COG数据库可以用来研究基因在不同物种之间的演化和功能差异;Swiss-port则可以运用于蛋白质结构、功能及相互作用等研究领域。
每个人都是站在巨人的肩膀上,除了上述的5个数据库以外,还有许多的数据库被广泛使用,对于数据库的灵活运用,就是我们合理运用前人研究基础以及进一步挖掘生物学意义的过程。
NR数据库网址:
https://www.ncbi.nlm.nih.gov/protein/
NT数据库网址:
https://www.ncbi.nlm.nih.gov/nucleotide/
GO数据库网址:
http://www.geneontology.org
KEGG数据库网址:
http://www.genome.jp/kegg/
KOG数据库网址:
https://www.ncbi.nlm.nih.gov/COG/
Swiss-Port数据库网址:
https://www.uniprot.org/
 微信公众号
微信公众号


 027-87224696
|
027-87224696
| marketing@frasergen.com
|
marketing@frasergen.com
|
